Label-Free 定量
随着设备的快速发展,非标记定量(label-free quantification,LFQ)技术开始成为定量蛋白质组学的有效可选方法,特别是当同位素标记或化学标记方法不可行,或过于昂贵时。
通过添加PEAKS Q 定量模块,用户可以在数据分析工作流程中运行非标记定量。该方法是基于至少两个样品中检测到的所有肽段特征峰的相对丰度。每个样品的肽段特征峰检测独立进行,并允许特征谱峰存在交叠。随后,使用高性能的保留时间对齐算法(以及IMS-MS数据的离子淌度对齐算法)将多个样品中的相同肽的特征峰可靠地对齐在一起。
结果解释
PEAKS Q模块生成一个用户友好的交互式结果页面,其中包括数据摘要以及每个肽段feature的更具体详细的信息。此外,易于操作的结果过滤器允许用户通过过滤大量参数来筛选非标记定量的数据,包括最小倍数变化、特有肽段的数量以及特定的电荷状态。
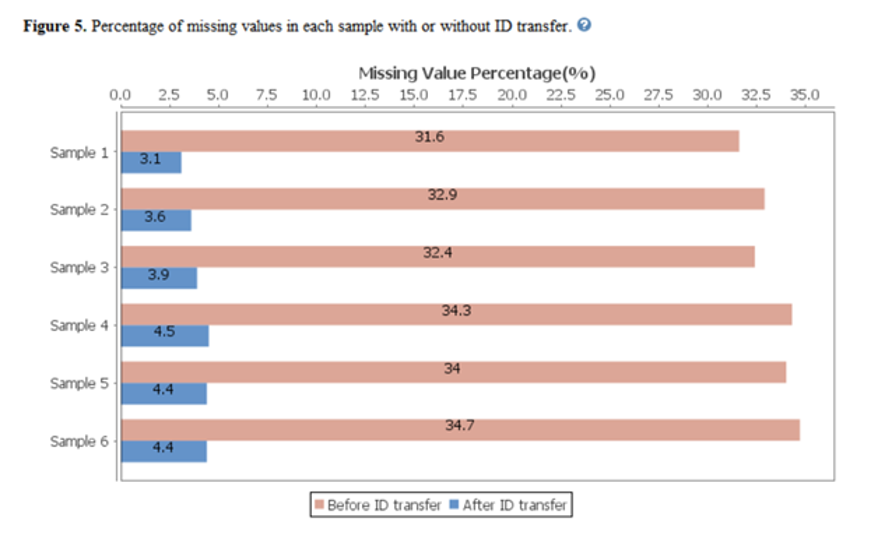
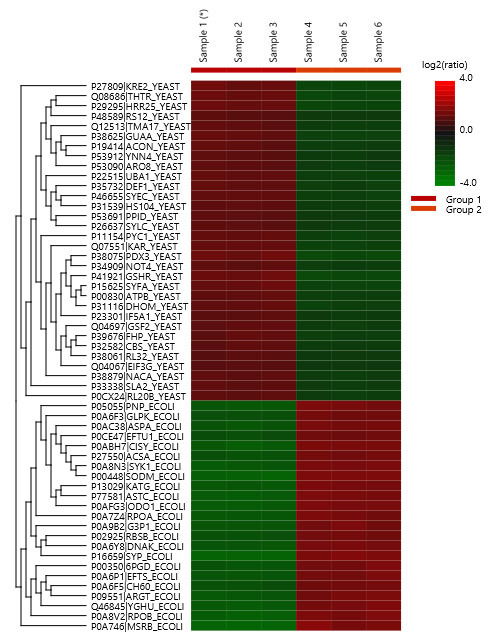
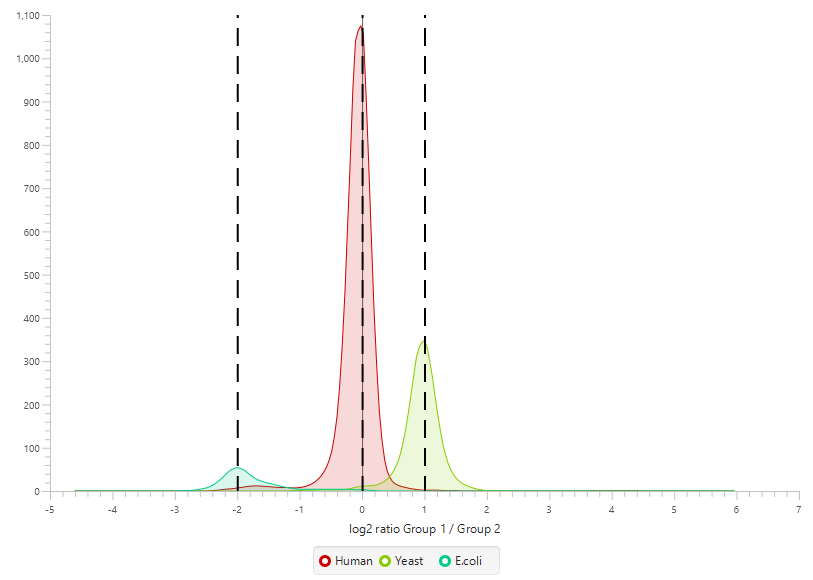
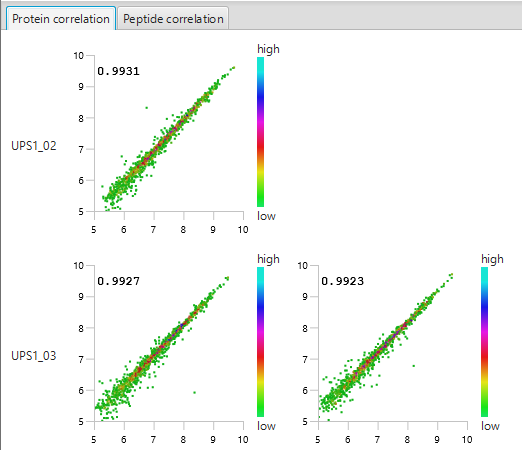
每次PEAKS Q的 LFQ搜索后的摘要报告包括样品总数据的质量和丰度,以及交互式热图(图1)、变化趋势、蛋白质密度比例(图2)以及蛋白、肽段和feature相关性分析图(图3)。最后,图表概述显示了ID- Transfer(match between run)之前和之后缺失值的百分比(图4)。此图表可以快速提醒用户鉴定结果中的任何异常值样本。
PEAKS LFQ的结果视图旨在让人轻松获取从一组到另外一组蛋白质发生的显著的变化。 因此,并不是所有的蛋白质都显示在默认结果中。不过,只需更改参数设置中的Q部分过滤参数,递交任务可快速重新整合结果,轻松查看所有定量的蛋白质。
缺失值和ID Transfer
非标记定量方法通常用于大队列生物样本的蛋白质组学层面上的定量分析研究。 为了数据解释的可靠性,运行时的 ID transfer对于降低假缺失值至关重要。假缺失值是由数据依赖性采集(DDA)的随机性和二级质谱图解析的困难性造成的,典型地如在直接数据库搜索中包含多个共碎裂的母离子,以及在数据非依赖性采集(DIA)中使用基于谱图库的多肽鉴定得到的定量深度有限。通过ID- Transfer,可以显著减少缺失值。
使用PEAKS Q,非标记定量的工作流程使用基于MS2的定性和MS1的定量方法。在PEAKS X+ 中提供的图表展示,可以让用户轻松评估在运行PEAKS ID- Transfer算法之前缺失值的比例。