PEAKS Glycan Analysis
PEAKS Glycan Module是PEAKS Studio的可选功能模块,为深入分析糖蛋白质组学提供高灵敏度和高准确度的独特解决方案,该模块利用基于糖肽的方法来分析LC-MS/MS数据中的糖蛋白。作为PEAKS Studio软件的一部分,PEAKS Glycan使用了优化的数据库搜索方法和全新算法来完成N糖和O糖的定性和表征。糖谱分析是在蛋白质的特定位点进行的(位点谱分析),并通过非标记定量比较不同样品间的糖肽丰度。目前,PEAKS Glycan Module支持ThermoFisher和Bruker等仪器产生的质谱数据,工作流和分析参数的设置向导都非常简单易懂,尤其是对于PEAKS软件的用户来说,界面将会非常熟悉。
蛋白糖基化
蛋白质糖基化是指糖基或聚糖附着在蛋白特定氨基酸上的反应,是最重要的翻译后修饰之一,在众多生物学过程中起着关键作用。据估计,蛋白质组中50%以上的蛋白质是糖蛋白。聚糖是一种基于碳水化合物的异质结构,可以是线性的,也可以是支链的,附着在糖蛋白内的氨基酸侧链上。糖蛋白中的聚糖可分为N糖,即与天冬酰胺氮原子(N)结合,或O糖,即与丝氨酸(S)或苏氨酸(T)侧链的氧原子结合。重要的是,糖基化可以影响蛋白质的结构、稳定性和功能,对生理和病理功能都有很大影响。
糖蛋白质组学和质谱
糖蛋白质组学是从给定的细胞或组织蛋白质组中鉴定聚糖和相关的糖基化位点。在蛋白质水平上,氨基酸序列或单个氨基酸被用来预测糖基化发生的位点。来自MS/MS的碎片数据用于鉴定这些位点和附着的N-或O-链聚糖结构。过去,基于LC-MS/MS的糖蛋白质组学分析一直面临样品中分子复杂性的挑战,导致包括潜在多肽序列,聚糖和其他PTMs在内的search space非常庞大。PEAKS Glycan的设计初衷就是应对质谱糖蛋白组学的这些挑战,它是一个全面的数据分析工具,提供了一个高灵敏、高准确的糖蛋白质组学软件解决方案。
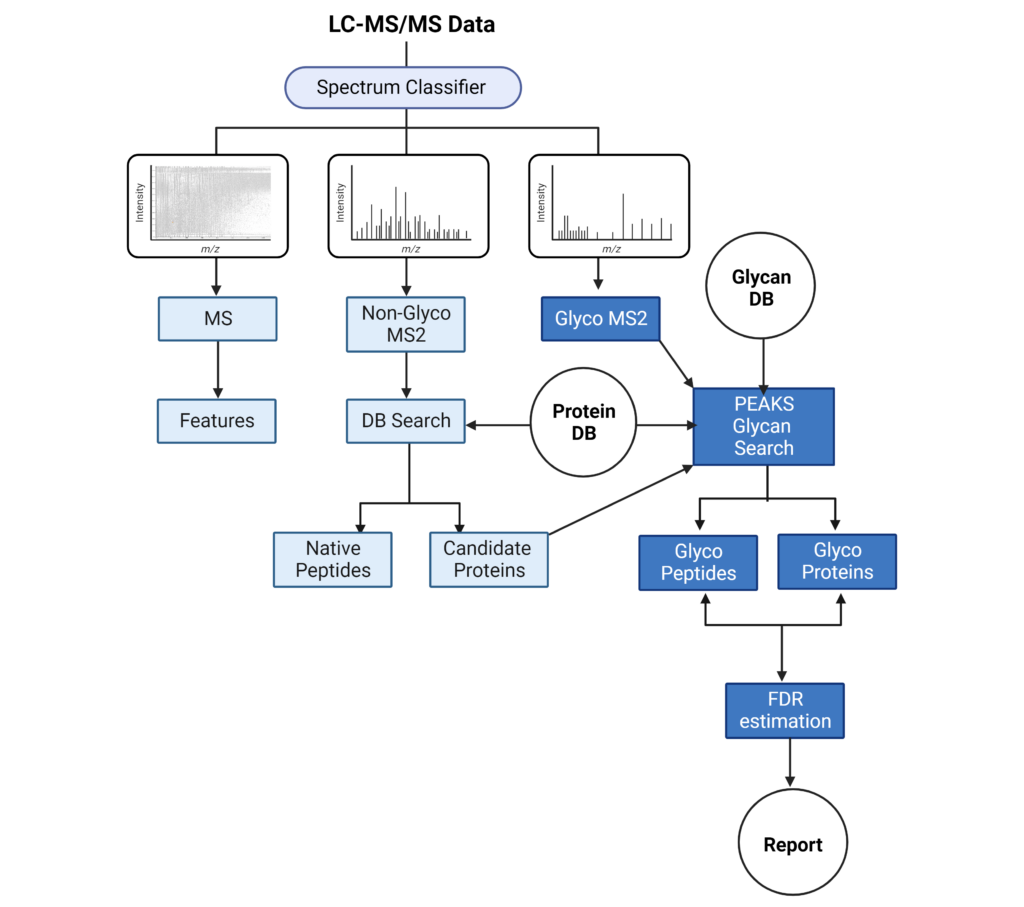
读取数据之后,软件的谱图分类器将首先把所有的谱图分为MS1,MS2糖谱和MS2非糖谱。MS1用于特征峰的提取,MS2非糖谱进行搜库(DB search)得出蛋白和肽段鉴定结果。MS2糖谱进行蛋白数据库和糖库搜索以完成聚糖和多肽序列的鉴定,并通过FDR阈值过滤结果。分析结束后,上述结果将会报告在Protein和Glycopeptide表格中。
从搜库参数到结果总结,获得完整分析的要点
Glycan搜索的参数设置界面涉及的重要参数有Error Tolerance、Enzyme、Digest Mode、Missed Cleavage、PTMs和Enrichment Data。
果总结页面提供了PEAKS Glycan分析的结果概览和数据的质控。统计表格和糖基化位点表格用于实验中每个样本鉴定结果的快速浏览。
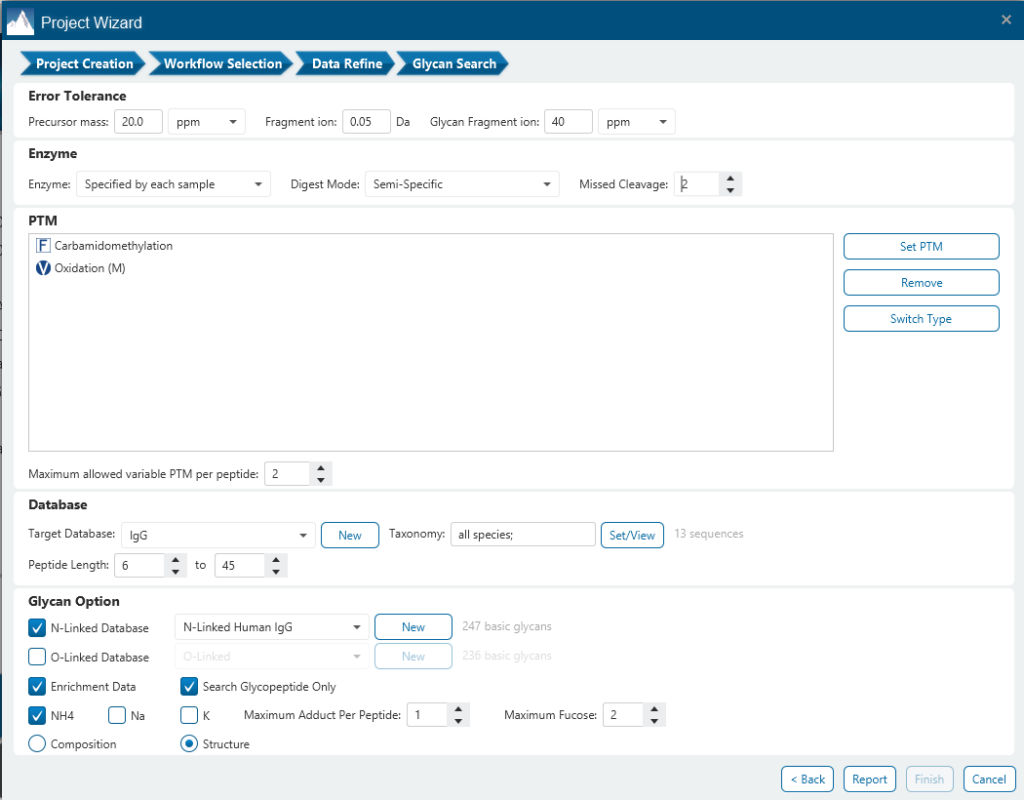
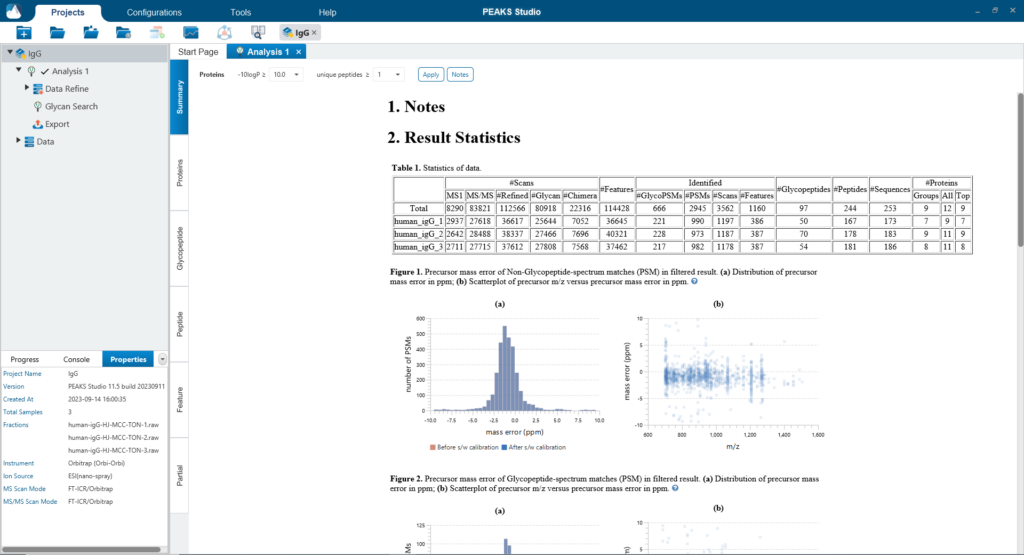
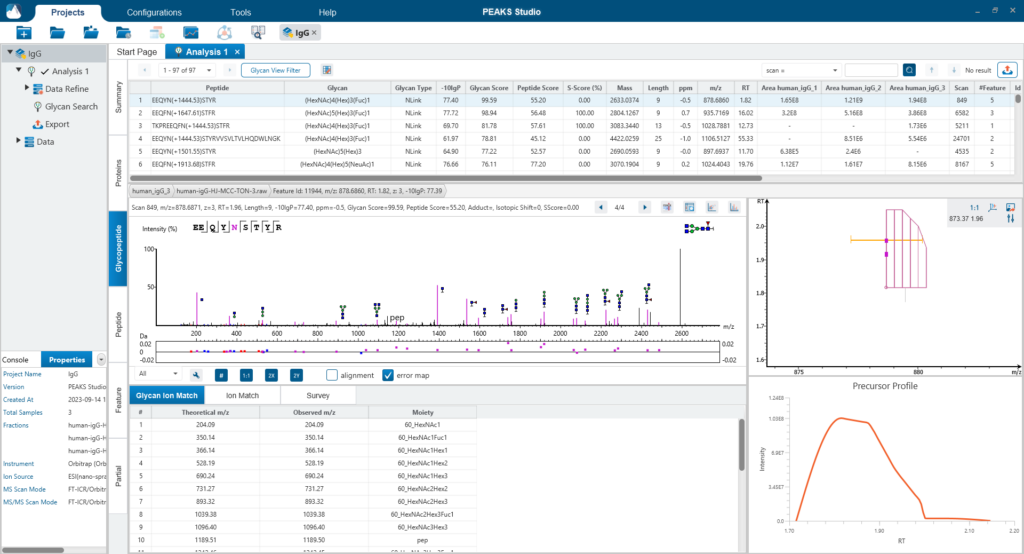
用户图形界面(GUI):与其他PEAKS产品一样,PEAKS Glycan界面设计易于理解、可视化和手动验证,以帮助研究人员轻松实现其研究的总体目标。直观的汇总统计和蛋白质视图为用户提供深入的数据分析和对样品中存在的糖蛋白的有参考意义的注释。
蛋白质覆盖视图
蛋白质覆盖视图(Protein Coverage View)以可视化的形式将该蛋白的归属肽段和de novo标签映射到所选中的蛋白中。它还显示了所有具有修饰或突变的鉴定位点,以协助在氨基酸水平上进行蛋白质表征。
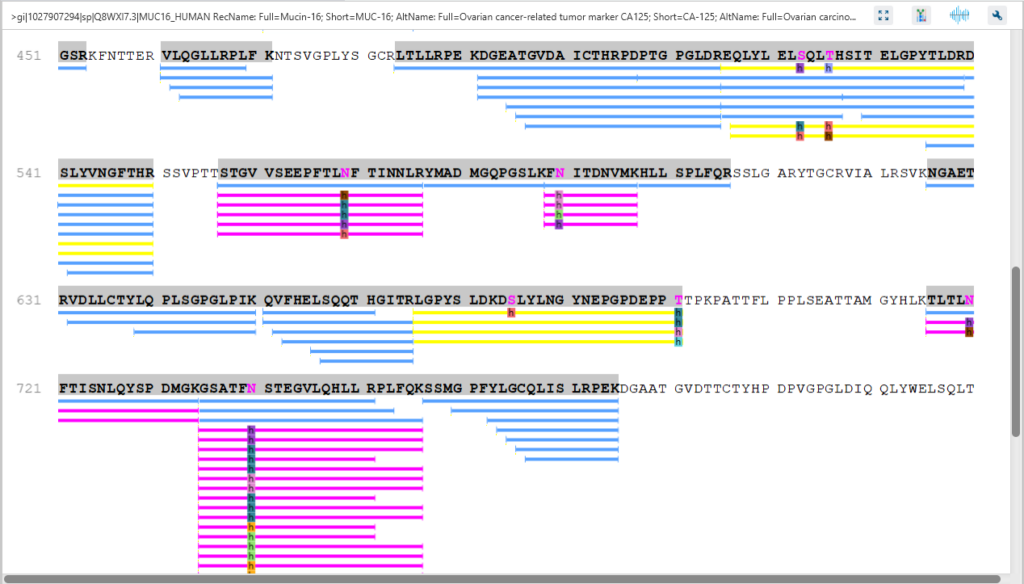
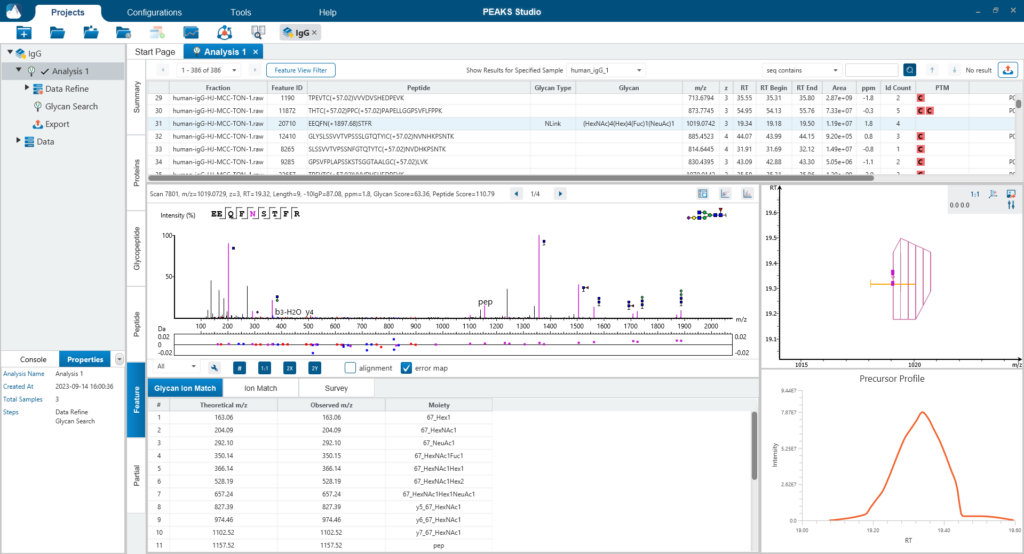
蛋白质视图(Protein View)显示的是从复杂生物样品中鉴定到的蛋白质。对于每个蛋白质,序列覆盖视图显示每个蛋白质的多肽匹配,并且结果是交互式的,因此用户可以直接点击查看每个肽谱匹配。用户可以很容易地通过颜色判断肽段类别,蓝色表示搜库匹配到的肽段,紫色表示N糖肽和橙色表示O糖肽。点击某一个蛋白质的糖基化位点(N,S,T为紫色),将以表格形式和饼状图的形式显示聚糖的分布。
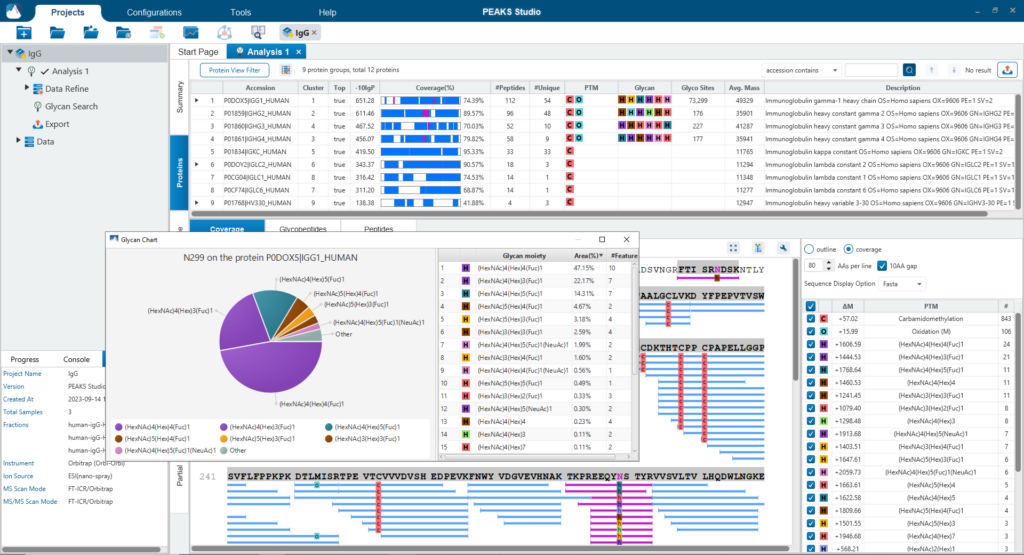
Glycan Profiling
聚糖分析(Glycan Profiling)功能将蛋白质的每个糖基化位点上鉴定到的所有聚糖进行可视化展示,包括样品中糖肽的相对丰度。筛选工具提供了自定义视图和聚糖列表、图表的展示,表格数据可以轻松导出。Glycan XIC图显示的是被选定的糖在不同样本中所对应的糖肽的XIC。Glycan Site Profile显示了每个糖型在不同样本间积分面积的分布。
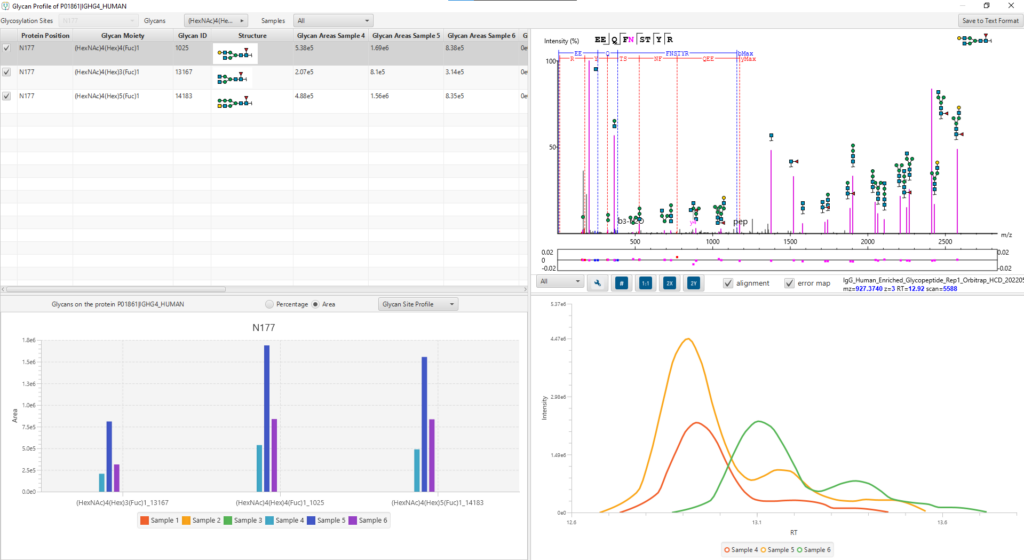
糖肽视图
糖肽视图(Glycopeptide View)提供所有鉴定到的糖肽列表。对于每个糖肽,选中之后,下方会展示对应的糖谱匹配注释。注释谱图可以在多肽离子和聚糖离子之间切换查看,并可以根据用户的个性化需求进行谱图的标注。该表与View Filter选项相结合,可视化更灵活。
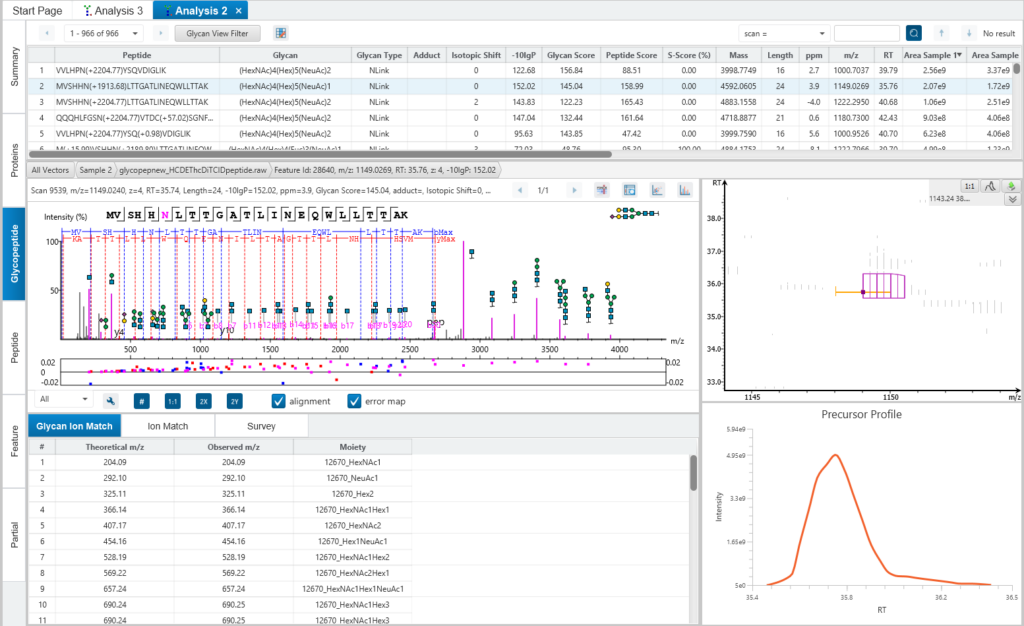
糖基化位点精确度(A-Score)
PEAKS Glycan通过A-score在MS/MS水平对糖基化位点进行精确鉴定。A-score通过-10logP计算,P表示糖基化位点随机匹配的可能性。因此,A-score越大说明这条肽段上匹配到该糖基化位点的可信度越高。
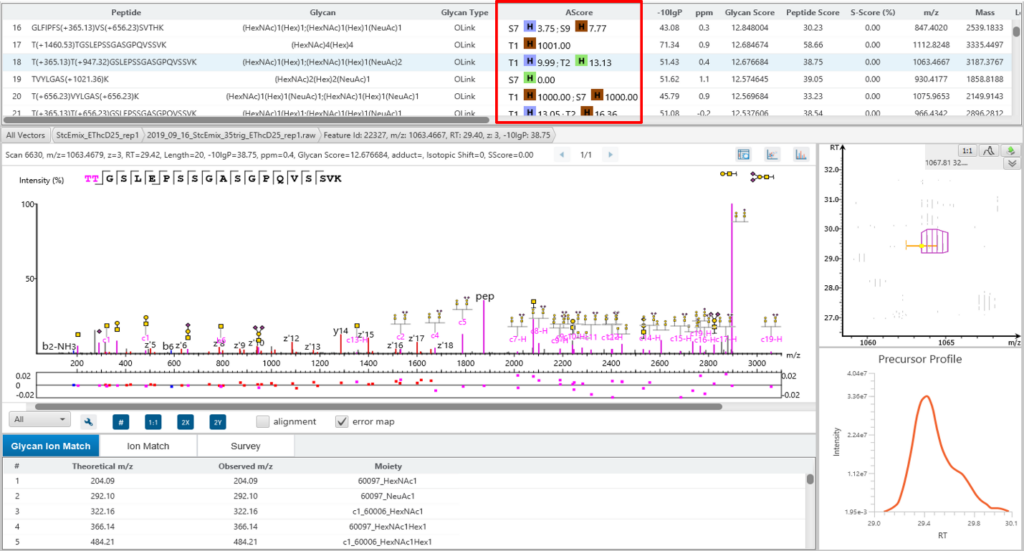
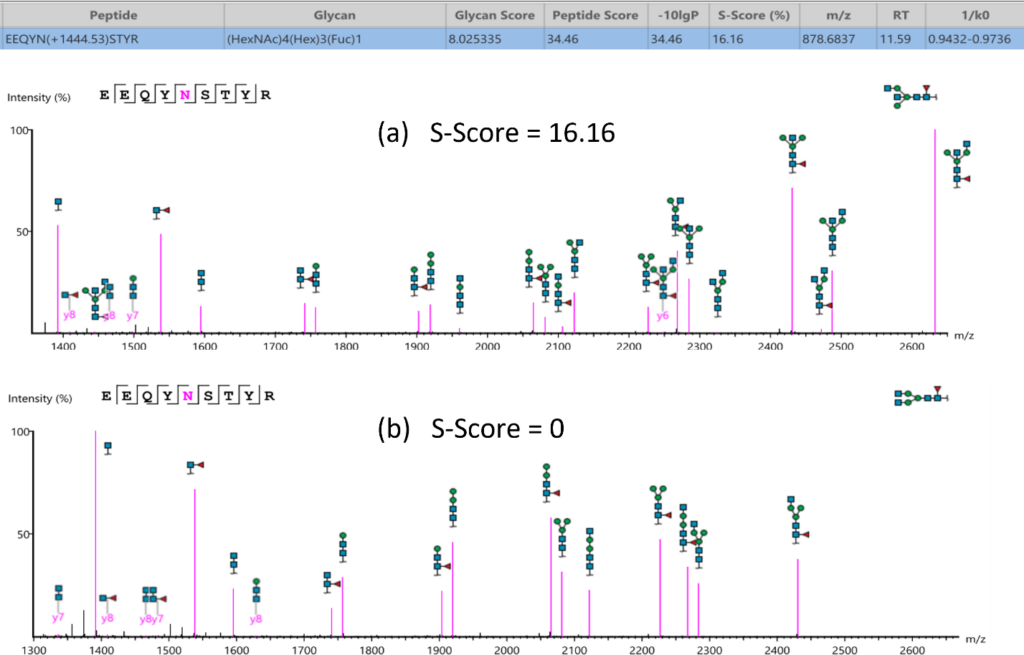
糖链结构特异性 (S-Score)
糖肽上的聚糖鉴定都会给出一个S-Score(%),表示糖库中匹配到该糖链组成的糖型的匹配可信度。对于糖库中相同组成成分的糖型,候选糖链会按照糖的Y-ion数量排序,S-Score的计算公式为:S-Score = (most Y-ion count – 2nd most Y-ion count)/(most Y-ion count)。S-Score得分越高越好,100%意味着只有1个候选糖链结构并且匹配地非常好。0%意味着top1和top2的结构非常相似,无法确切地说哪个是最佳匹配。
特征峰视图
特征峰视图(Feature View)包括所有用于鉴定和定量的多肽和糖肽的母离子特征峰。对于多个样本的项目,这里展示的是特征峰向量(Feature Vector)。详细的图形可视化便于快速对结果进行确证。